Pythonからエクセルのファイルのデータの読み込み、書き込みも可能です。
これならPythonのほうで処理を書いて実行できるので、処理内容によってはVBマクロを書くよりも楽になるでしょう。
Pythonでエクセルファイル

準備
「pandas」というモジュールを使うとかなり簡単にエクセルファイルを利用できます。
「pip install pandas」で先にインストールしておきましょう。
Visual Studioでのpipインストール方法は以下参照ください。
エクセルファイルを読む
ファイル名、シート名を指定してみると、
import pandas as pd
myfile = "sample.xlsx"
try:
mysheet= pd.read_excel(myfile,sheet_name="Sheet1")
print(mysheet)
except Exception as e:
print(e)
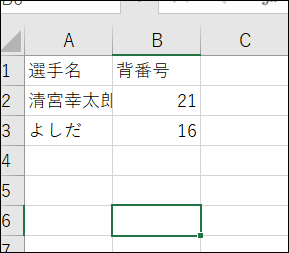
こちらは元ファイル。
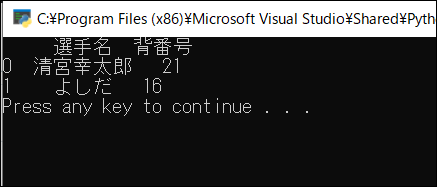
こちらは出力。日本語が文字化けということもありません。
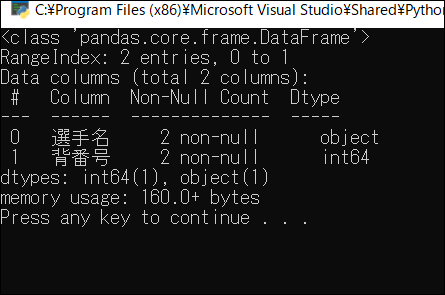
取得したデータはデータフレームと呼ばれる形式になります。info関数で詳細を確認することができます。
myfile = "sample.xlsx"
mysheet= pd.read_excel(myfile,sheet_name="Sheet1")
mysheet.info()
読み込みではいろいろと設定を変更できるので、詳細は以下参照ください。
pandas.read_excel — pandas 1.1.4 documentation
セル情報の取得
セルをピンポイントで取得するには配列から情報を取得できます。
read_excelで取得したオブジェクトの「values」プロパティを2次元配列として指定します。
print(mysheet.values[0][0])
print(mysheet.values[0][1])
また、取得したデータはDataFrameという形式のため、以下のような関数でセルの値を取得することもできます。
print(mysheet.iloc[0,1])
ただDataFrame形式は自動的に1行目をインデックスにしたりしているっぽいのでもうちょっと調査が必要です。
セル情報の変更
pandasを利用すると楽になる部分がある一方、面倒なところもありました。
取得したデータはDataFrameという特殊なつくりになっており、単純に取得したシートの配列を変更するだけではだめでした。
いろいろためしたところ「iloc」というメソッドを使って変更できました。
mysheet.iloc[0,1] = "110"
エクセルファイルの保存
「to_excel(ファイル名、シート名)」でファイルに保存できます。
try:
mysheet.to_excel("sample2.xlsx","Sheet1")
except Exception as e:
print(e)
ただ、うちで実行するとなぜか頭に不要な1列が追加されていました。
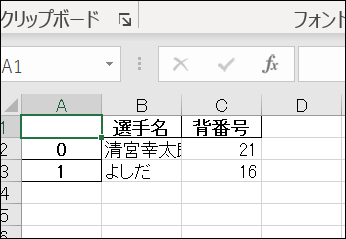
対策としては「index=False」として「indexは不要です」というパラメータを追加したら大丈夫でした。
mysheet.to_excel("sample2.xlsx","Sheet1",index=False)
CSVファイルの保存
「to_csv(ファイル名)」でファイルに保存できます。
try:
mysheet.to_csv("sample2.csv")
except Exception as e:
print(e)
エラーの場合
xlwt, openpyxlがない!
ファイルの書き出しでは、
「xls」形式の場合は「xlwt」がない!とエラーになりました。
「xlsx」の場合は「openpyxl」がない!とエラーになりました。
それぞれ「pip install xlwt」「pip install openpyxl」でインストールできます。
Missing optional dependency 'xlrd'. Install xlrd >= 1.0.0 for Excel support Use pip or conda to install xlrd.
また、うちで実行したら次のようなエラーが出ました。
「Missing optional dependency 'xlrd'. Install xlrd >= 1.0.0 for Excel support Use pip or conda to install xlrd.」
エラーが出る場合の対策として「pip install xlrd」を実行しておきましょう。
list.remove(x): x not in list
リストに該当が見つからなかった場合のエラー。