Pythonはスクレイピングなどによく利用されます。
ここではネット関連の関数について紹介してきます。
Pythonでネットを扱う関数のまとめ
ライブラリで必要なものはあらかじめインストールしましょう。
ホスト名の取得
socketライブラリを利用します。
import socket print(socket.gethostname())
IPアドレスの取得
ホスト名を渡してIPアドレスを取得します。
import socket myhost=socket.gethostname() print(socket.gethostbyname(myhost))
pingを送る
pingはサーバが稼働しているかどうか調べるために利用します。
ここでは「pings」というライブラリを利用するため、事前に利用可能にしておく必要があります。
import pings
p = pings.Ping()
res = p.ping("komatter.com")
res.print_messages()
実行し、サーバがもんだしなければこのように何バイトがどのぐらいの秒数をへて送られてきたかわかります。

ウェブページのテキストを取得
Requestsというライブラリを使ってウェブブラウザを開くことができます。
このライブラリはpipであらかじめ利用できるようにインストールしておく必要があります。
以下は、reuestsを使って取得後、textを出力させています。
import requests
response = requests.get("https://komatter.com/")
print (response.text)
で、実行すると、このようにコンソールへHTMLのソースコードが表示されます。
このコードをさらに正規表現などで分解すると、特定のデータを取得できることになります。

PDFのテキストを取得
PyPDF2を使うとPDFのハンドリングをPythonから行うことができます。
あらかじめPyPDF2ライブラリをインストールしておきます。
以下は「sample.pdf」を開き、PyPDF2を使ってロードします。
1ページ目の情報を取得し、「extractText」で文字データを抜き出しています。
import PyPDF2
fn = 'sample.pdf'
with open(fn, mode='rb') as f:
reader = PyPDF2.PdfFileReader(f)
page = reader.getPage(0)
print(page.extractText())
ブラウザの起動
Webbrowserというライブラリを使ってウェブブラウザを開くことができます。
このライブラリはpipでインポートしなくても利用可能です。
ただしこのライブラリはインターネットエクスプローラが既定となっているためかIEが起動してしまいます。
import webbrowser
webbrowser.open("komatter.com")
Pythonで正規表現

Pythonでは「re」モジュールを使って正規表現による処理をいろいろとおこなうことができます。
「import re」を宣言してから処理を行いましょう。
reの使い方
検索
「findall」関数で、指定した正規表現をすべて探します。
以下は文章から「<h1>」と「</h1>」で囲まれた文章をすべて探します。
sampletext = "<title>Tokyo</title><h1>東京</h1>東京のページです。"
pat = re.findall( '<h1>.*?</h1>', sampletext)
for p in pat:
print(p)
実行すると「<h1>東京</h1>」という文字が出力されます。
置換・削除
正規表現に該当した個所は「sub」関数で置き換えることができます。
「''」と置き換えれば、削除にもなります。
以下は数字以外の部分を削除しています。
mystr = "1,100円"
result = re.sub(r"[^0-9]", "", mystr)
print(result)
結果は「1100」となります。
サンプル
郵便番号
郵便番号は3桁の数値「d{3}」と4桁の数値「d{4}」をハイフンでつないだものです。
長さが固定ですし数字のみのですので、正規表現「\d{3}-\d{4}」で指定すればオッケーです。
sampletext = "〒123-4567 東京都千代田区国会議事塔"
pat = re.findall( '\d{3}-\d{4}', sampletext)
for p in pat:
print(p)
実行すると「123-4567」となります。
電話番号
電話番号は2~4桁の数値「\d{2,4}」と4桁の数値「d{4}」と4桁の数値「d{4}」をハイフンでつないだものです。
これを正規表現で指定するには「\d{2,4}-\d{4}-\d{4}」と記述します。
sampletext = "東京都千代田区国会議事塔 電話03-1234-5678"
pat = re.findall( '\d{2,4}-\d{4}-\d{4}', sampletext)
for p in pat:
print(p)
実行すると「03-1234-5678」となります。
ドコモ携帯の「090」などと数字が決まっている場合には「090-\d{4}-\d{4}」のように指定できます。
Pythonでスクレイピング

スクレイプは削る、こする...といった意味です。
スクレイピングは、IT関連的にはウェブからページを取得して必要な部分を切り出すことを意味します。
最新の株価や、ネットショップの特定商品の現在価格など、必要な情報はウェブ上に公開されていることが多いです。
よって、プログラムで定期的に取得することで、分析しやすくなります。ただ過度なスクレイピングは無駄な負荷をサーバにかけることになります。スクレイピングをかける時間間隔を大きくとるなどのマナーは必要でしょう。
ウェブページをダウンロードする
まずはウェブページをひっぱってきましょう。
そこで便利なのが「requests」というモジュールです。
「pip install requests」でインストールします。
あとは「import requests」で利用を宣言。「requests.get(URL)」でウェブページを取得して「text」プロパティを表示させます。
import requests
site = requests.get("https://komatter.com")
print(site.text)
実行するとウェブページのソースが取得できました。
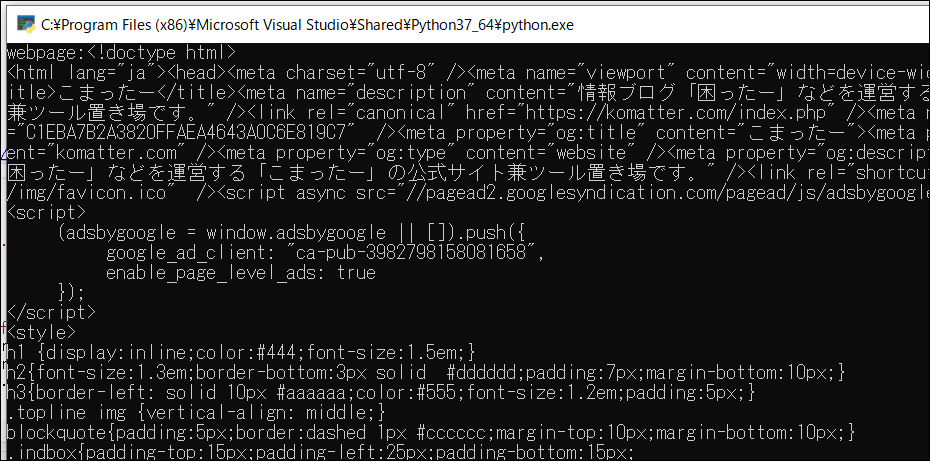
ウェブページのソースから文字を切り出す
正規表現を使って文字を切り出す
HTMLタグを正規表現を使って抜き出すことができます。
正規表現は最初は複雑で慣れるのが大変ですが、一度慣れてしまえばかなり文字操作には強くなると思います。
Pythonでは正規表現は「re」モジュールを使い、指定した表現にマッチする文字列を抜き出すことができます。
以下は<b>と</b>ではさまれた文字列を抜き出す場合です。「r'<b>(.+?)</b>」と規則を記述して「findall」で実行します。
import re
pattern = r'<b>(.+?)</b>'
mylist = re.findall(pattern, site.text)
for i in mylist:
print( i )
抜き出したら、リストから1つづつ確認用にprintしています。
BeautifulSoupを使って切り出す
正規表現はマスターするのが面倒ですが、もっと簡単にHTMLの情報を抽出できるライブラリがあります。
「BeautifulSoup」はその1つで、「pip install beautifulsoup4」でインストールします。
まず上記に書いたRequestでサイトの情報を取得します。
そのデータをBeautifulSoupに渡した後は、簡単に情報を抽出できます。
以下はウェブページのタイトル文を取得するサンプルです。
from bs4 import BeautifulSoup
data = BeautifulSoup(site.text, "html.parser")
print(data.title.text)
タグの抽出もらくちんで、以下は「a」タグをリストアップしています。
print(data.find_all("a"))
株価を取得する
株価をウェブページから取得して、そこから自分で切り出すこともできます。
そのための専用モジュールがすでにありますので、そちらを利用するとかなり簡単に作業を行えます。
まず「pandas_datareader」を「pip install pandas_datareader」でインストールしておきます。
以下はパランティア(PLTR)のデータを日にちを指定してダウンロードしてCSVとして保存しています。
import pandas_datareader.data as web
from datetime import datetime
myticker = "PLTR"
start = datetime(2020, 10, 1)
end = datetime(2020, 12, 5)
df = web.DataReader(myticker,"yahoo",start,end)
df.to_csv(myticker + ".csv")
米国版ヤフーからデータを入手しているため、日本株の場合、例えば住友金属鉱山なら「5713.T.」がティッカーとなります。
指数にも結構対応しています。主なものは以下。
- 日経平均:%5EN225
- SP500:ES=F
- 石油価格:CS=F
- ゴールド:GC=F
- シルバー:SI=F
- VIX:%5EVIX
- 10年債:%5ETNX
ビットコインなどの情報も取得できます。
ティッカーのところで
- ビットコイン:BTC-USD
- ライトコイン:LTC-USD
- イーサリアム:ETH-USD
- リップル:XRP-USD
のように指定します。