Pandasの使い方のまとめ
Pandasとは?呼び方は?

Pandasはデータを効率的に扱うためのパッケージです。
Pandaの正体は「PANel DAta=パネルデータ」。
「pip install pandas」でインストールできます。
呼び方ですが、海外の動画を見たりしていると「パンダス」と呼んでいるようです。
Numpyとの違いは?
Numpyは「num」とあるように数字に特化したデータ構造です。それに対しPandasは広範囲にいろんな型のデータが含まれ、各種のデータ分析に役立つようになっています。
PandasはNumpyの上位的な存在であり、PandasをインストールするとNumpyも自動的にインストールされます。
Pandasは多機能なので数次配列でシミュレーションするならNumpyだけでも十分なように思います。
Pandasの使い方
パッケージのインポートを行ってから使います。
import pandas as pd
データの初期化
Pandasで使われるデータ形式が「DataFrame」です。
「DataFrame」は2次元のデータ構造で、「DataFrame」関数で作成することができます。
・リストで初期化します。
mylist= [["Judge",18],["Ohtani",15],["Trout",12]]
df= pd.DataFrame(mylist)
print(df)
出力は
0 1
0 Judge 18
1 Ohtani 15
2 Trout 12

「columns」を引数にしてラベル名をつけることもできます。
・辞書型で初期化します。
以下のように辞書型リストから初期化できます。
mydict= {"Name" : ["Judge","Ohtani","Trout"], "Homerun" : [18,15,12]}
df= pd.DataFrame(mydict)
print(df)

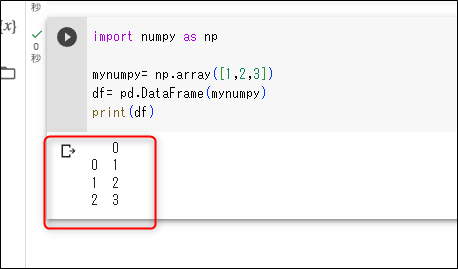
・Numpyからも初期化できます。
import numpy as np
mynumpy= np.array([1,2,3])
df= pd.DataFrame(mynumpy)
print(df)
さらに以下のような指定も可能。
import numpy as np
mynumpy= np.array([["Judge",18],["Ohtani",15],["Trout",12]] )
df= pd.DataFrame(mynumpy)
print(df)

データの確認
全部見ると大変ですが、部分的に表示して確認する方法があります。
「head」なら、最初から指定した分の行数を表示。
df= pd.DataFrame( [["Judge",18],["Ohtani",15],["Trout",12]])
df.head(2)

tailで最後から指定した分の行数を表示。
df= pd.DataFrame( [["Judge",18],["Ohtani",15],["Trout",12]])
df.tail(2)

データの抽出
条件をつけてデータを抽出することができます。
・条件付きの配列を出力
データフレームをつくった後、ホームラン数が15本以上の選手を抽出。
mydict= {"Name" : ["Judge","Ohtani","Trout"], "Homerun" : [18,15,12]}
df= pd.DataFrame(mydict)print(df[ df['Homerun'] >= 15])

・queryとして検索条件を渡す
queryとして「'Homerun >= 15'」のようにホームラン数の基準を渡しています。
mydict= {"Name" : ["Judge","Ohtani","Trout"], "Homerun" : [18,15,12]}
df= pd.DataFrame(mydict)print(df.query('Homerun >= 15'))

データフレームを作った後、大谷選手のデータを抽出
mydict= {"Name" : ["Judge","Ohtani","Trout"], "Homerun" : [18,15,12]}
df= pd.DataFrame(mydict)print(df.query('Name == "Ohtani"'))

ファイル操作
・CSVを読む
df = pd.read_csv("csvファイル")
・テキストファイルを読む
区切り文字を指定できます。
df = pd.read_csv("テキストファイル", sep="区切り文字")
・データフレームをCSVに書き出し
df.to_csv("csvファイル")
データの加工
Pandasは機械学習用のデータとしてもよく使われます。その場合データにNaNがないようにしたり、差分をとったりなどの加工が必要になる場合があります。
変化率
「diff」関数で1行前の値との差分を取得します。
移動
「shift」関数で行をずらします。
shift()なら1行したへ、shft(-1)なら上へ一行。
加工
特定の行、列の値に計算式を定期用します。
倍にする
df['a'].apply(lambda x : x * 2)
値が3以上なら1、それ以外は0
df['a'].apply(lambda x : 1 if x > 3 else 0)
欠損
機械学習ではデータの抜け(欠損)などがあると計算がうまくいきません。そこで事前にデータに欠損がないかチェックしたりします。
欠けを調べる
まず欠損(NaN)のあるデータを作ります。
import pandas as pd
import numpy as np
data = {'A': [1, 2, np.nan, 4],
'B': [5, np.nan, 7, 8],
'C': [np.nan, 10, 11, 12]}
df = pd.DataFrame(data)
print(df)
「isnull」で欠損があるかチェックできます。
df.isnull().head()
欠損があればTrueとなります。
「isnull.sum()」で欠損の個数をチェックできます。
df.isnull().sum()

欠けを削除
「drop」で欠けがある行を削除できます。
df.dropna(how='any',inplace=True)
「how='any'」ではデータが1つでも欠損がある場合を指します。
欠けを埋める
欠損は「fillna」関数で置換できます。
df.fillna(10)
平均値で補うと、よりスムーズなデータになりそうです。
df.fillna(df.mean())
その他
移動平均
窓関数=rollingを使うことで、移動平均を算出できます。
df["SMA"] = df["Close"].rolling(window=25).mean()