Power Automate DesktopではPDFの処理にも威力を発揮します。
Power Automate DesktopでPDFの処理

今回は以下のような画像や文字の入ったPDFファイルを使って試してみました。

画像を抽出
「アクション」で「PDF>PDFから画像を抽出」を実行。PDFファイルの場所、画像名につける適当な名前、画像を保存するフォルダを指定します。
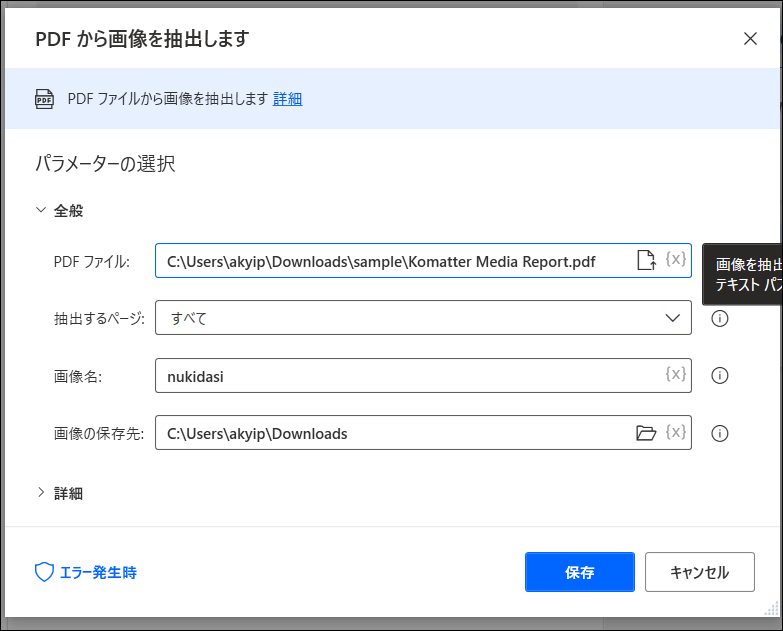
実行後、無事以下のように画像ファイルが書き出されていました。

テキストを抽出
「アクション」で「PDF>PDFからテキストを抽出」を実行。PDFファイルや抽出するページを指定します。
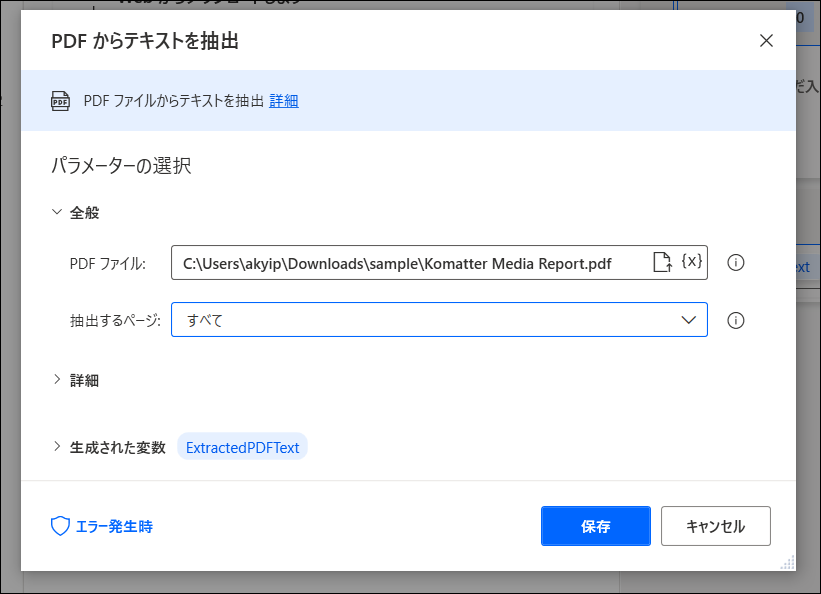
実行すると、右のフロー変数のところに文字が出てくると思います。ダブルクリックすると、抽出したすべての文字を見ることができます。
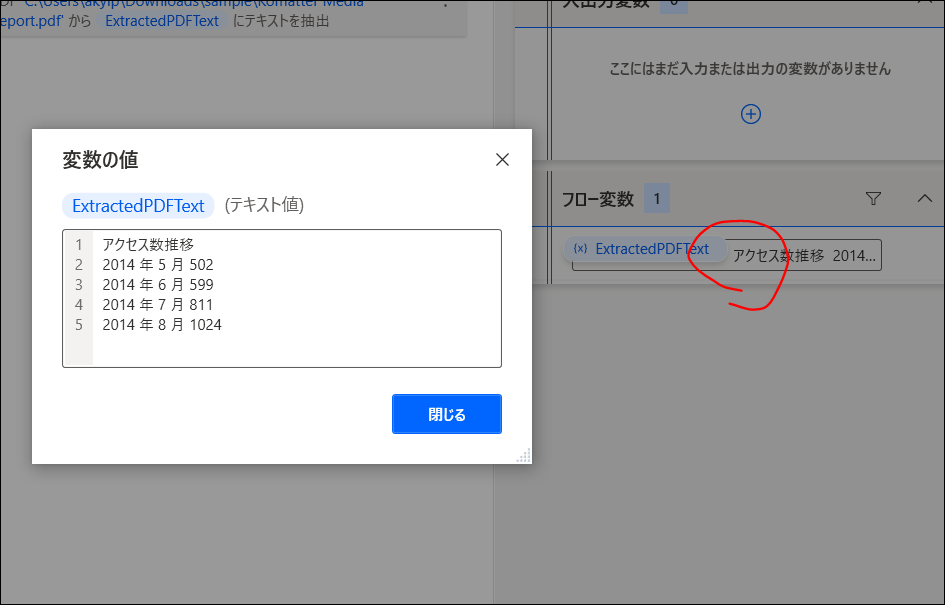
抽出した文字をテキストファイルに書き出す場合は、アクションで「ファイル>テキストをファイルに追加」を加えます。
書き出すファイルのファイルパスを追加。また、書き込むテキストでは、右のXマークを押すことでPDFから抽出した文字を入れておいた変数を選択することができます。
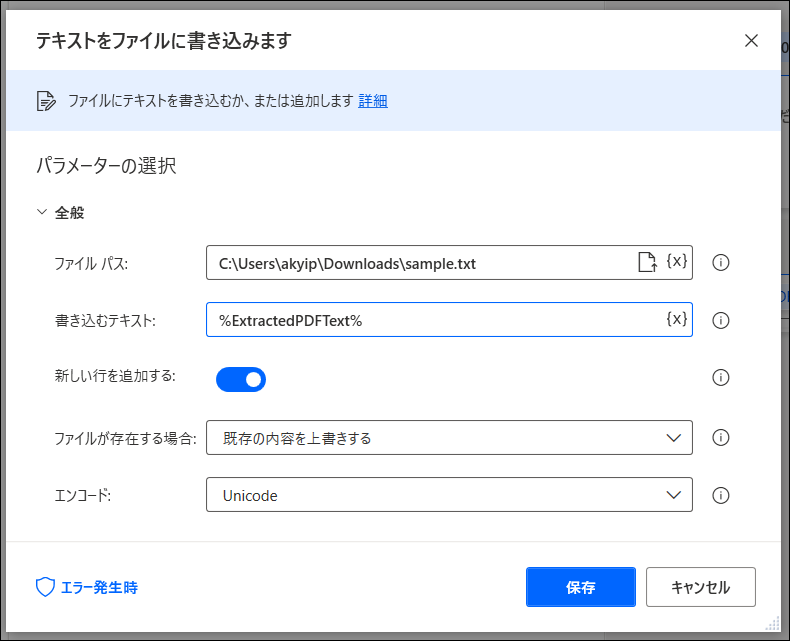
フローを実行し、テキストファイルを開くと以下のようにPDFから抜き出した文字を保存できたことがわかります。

Power Automate Desktopの導入方法や基本的な使い方については以下参照ください。