Power Automate Desktopを使えば、ウェブの情報を取得することも簡単に行えます。
ウェブの情報をスクレイプするには?

アクションで「Web」や「Webオートメーション」というのがあるので、それを使えばネットの情報を取得できます。
特定の情報をダウンロードするだけなら「Web」を、ブラウザを起動していろんな操作をするなら「Webオートメーション」を使います。
Web
特定のページをダウンロード
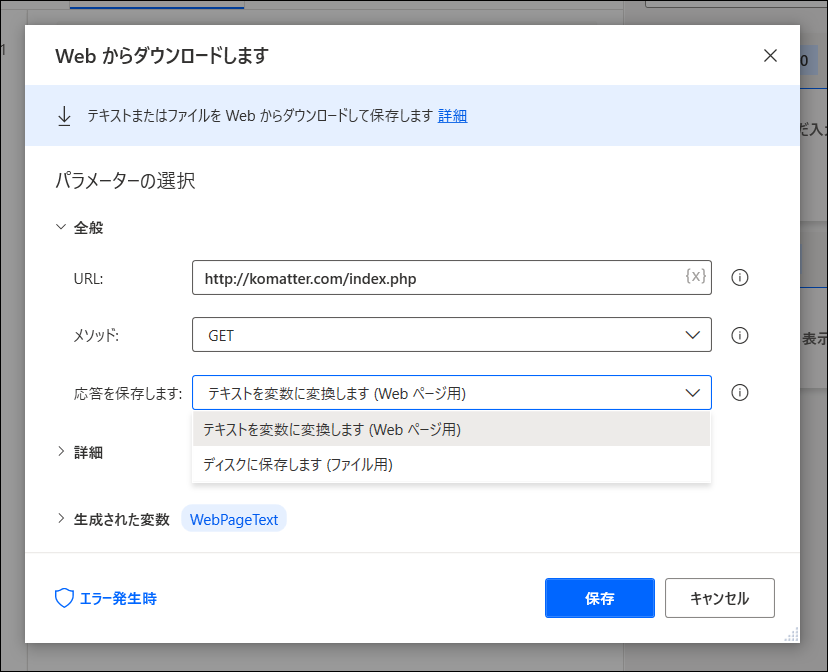
アクションで「Web」の「Webからダウンロードします」をドラッグします。
リンクや、ディスクに保存する場合には保存するファイル名を指定します。
後は実行して、実際にページの情報がファイルとして保存されているか確認してみましょう。
XMLの入手
同様にXMLファイルをダウンロードして、解析することもできます。
サイトによっては価格情報などをXMLで提供していますので、これが簡単に扱えるのは非常に便利です。
XMLの利用については以下参照ください。
FTP
FTPにも対応しています。
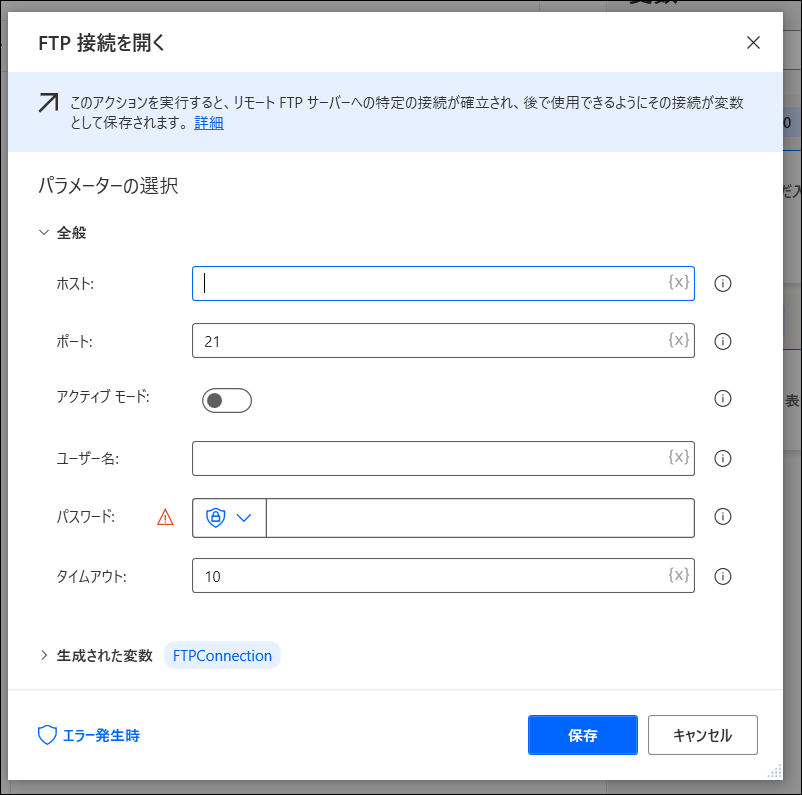
「FTP>FTP接続を開く」をフローに追加します。ホスト、ユーザ名、パスワードなどを指定します。
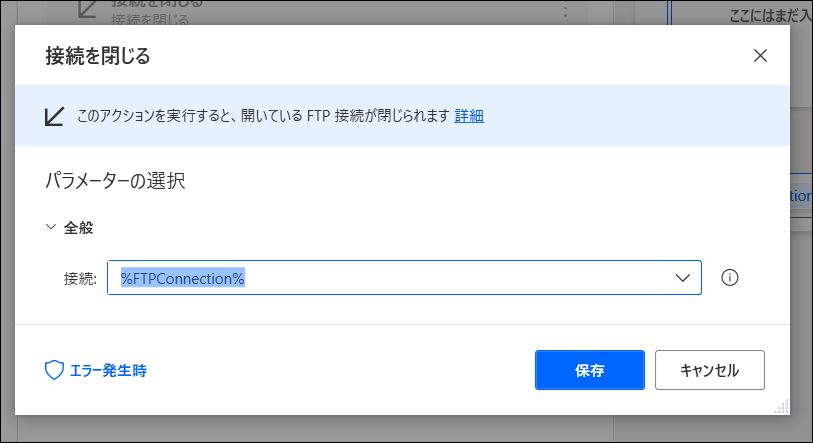
作業を追加し、終わったら「FTP>接続を閉じる」をフローに追加して完了します。
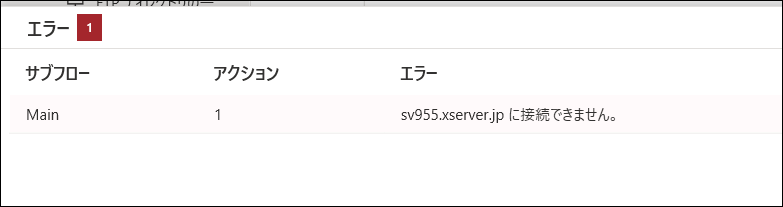
試しにやってみたらうまく接続できませんでした。現在調査中です。
Webオートメーション
こちらのセクションになると、クロームやファイアフォックスといったブラウザを起動していろんな操作を行うことができます。
クロームを起動する
アクションで「Webオートメーション」にある「新しいChromeを起動」を選び、ダイアログでURLを入れます。
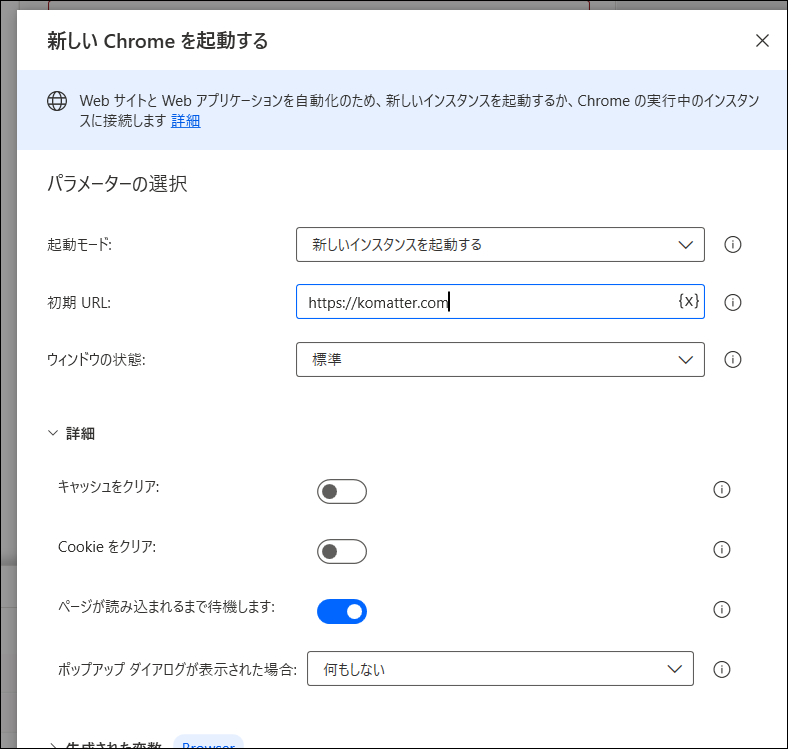
実行ボタンを押すと、クロームが起動して指定したURLへ切り替わっているはずです。

クロームを終了する
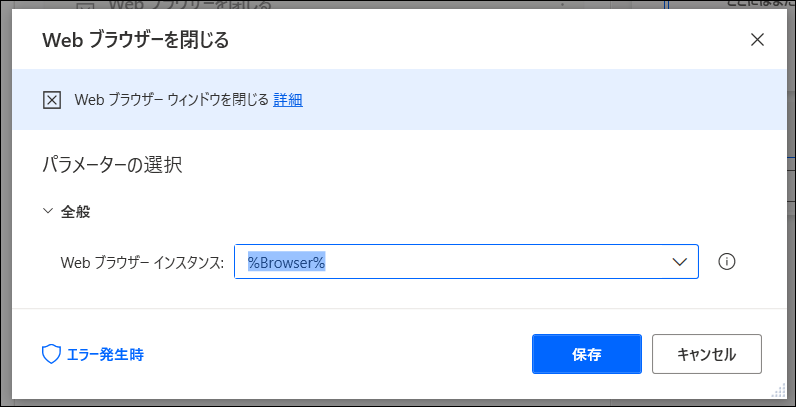
作業が終わってクロームを閉じる場合には、「Webオートメーション>Webブラウザーを閉じる」をフローに追加して終了させましょう。
ウェブページの情報を取得
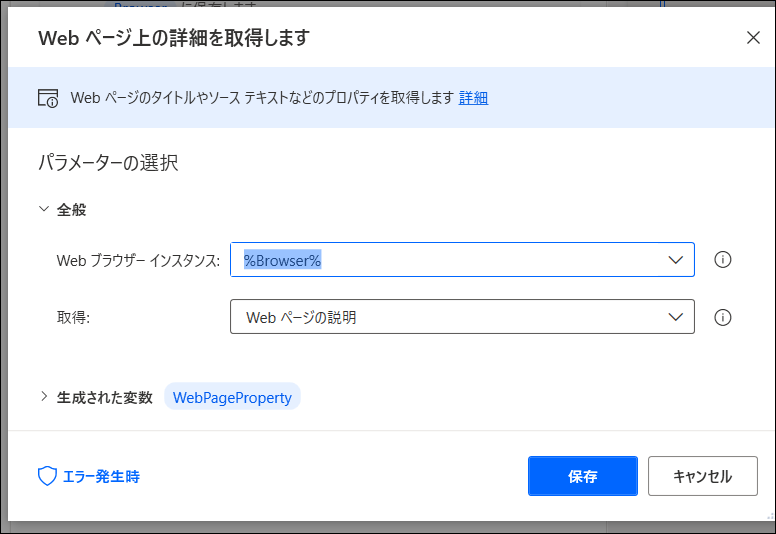
今度は「Webオートメーション」にある「Webデータ抽出>Webページ上の詳細を取得」をドラッグします。
ブラウザーインスタンスは、すでに先ほど作っています。
取得では「タイトル」や「ウェブページの説明」などを選びます。
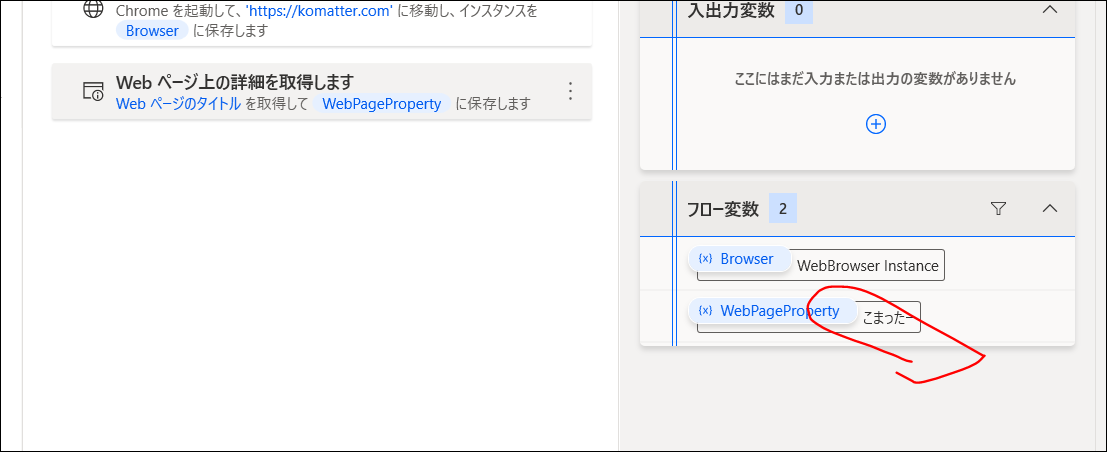
無事情報がとれたことが、右側の「変数」というところで確認できます。
スナップショットをとる
サイト自体のキャプチャ画像をとることもできます。
先にブラウザを起動させるフローを追加。
続いて「web>webオートメーション>Webデータ抽出>Webページのスクリーンショットを取得します」をフローに追加します。
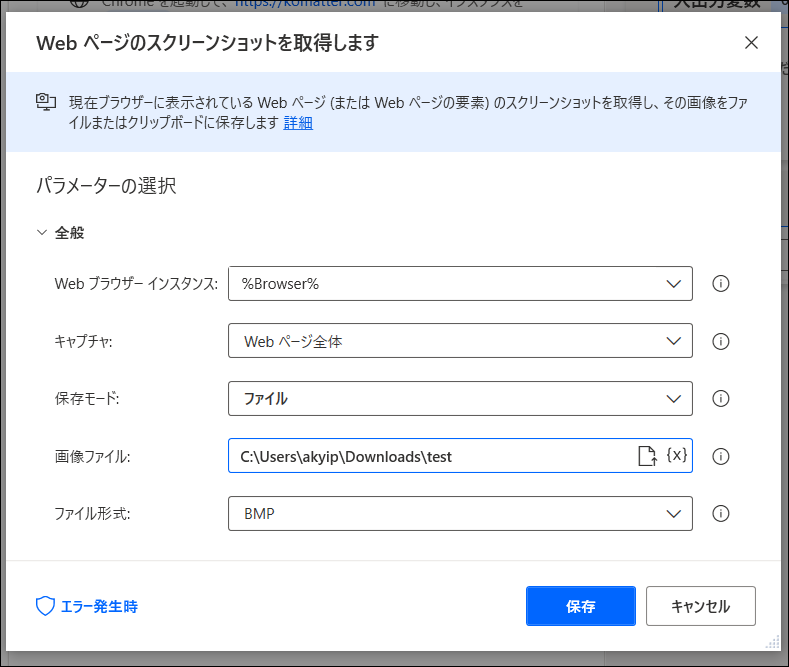
キャプチャ範囲や保存ファイルを指定します。
実行すると、サイト全体のキャプチャをしてくれます。
起動時にブラウザが変にスクロールして一瞬変な動作をしますが、これはページ全体を撮影するために強制的にスクロールしているためと思われます。
フォームを自動で設定して送信する
ウェブでは、アンケートや問い合わせなどいろんな情報をフォームから送信できます。
PADを使えば、その作業自体を自動化させることができます。
使い方については以下参照ください。
クロームを制御できない場合は?
ウェブの操作で「Chromeを制御することができませんでした」となることがありました。

クロームを扱う場合には、Power Automateのアドオンを入れないと正常に動作しないようです。
以下より入手します。
Microsoft Power Automate - Chrome ウェブストア
アドオンを入れた後に再度実行すると無事動きました。

Power Automate Desktopの導入方法や基本的な使い方については以下参照ください。