ChatGPTのウェブブラウジング機能を使えば、指定したURLから記事をひっぱってきて要約や加工が簡単に行われます。
これが困る場合は、以下のような対策をしておくといいかもしれません。
ChatGPTでウェブブラウジングされるのをブロックするには?

ChatGPTでは指定されたURLへアクセスしいろんな情報を取得できます。
これはこれで便利ですが、コンテンツを提供している側からすれば無断で情報だけ抽出される可能性もあります。
ですので、サイトによってはウェブブラウジングからサイトをブロックしたい場合もあるでしょう。
対策ですが、ChatGPTからのボットのブロックを「robots.txt」に書いておけばいいようです。
「robots.txt」は、ネット上のボットのコンテンツへのアクセス許可を記述するためのファイルとなります。ボットによって検索エンジンが巡回して登録してくれる反面、サーバへの負荷となる可能性もあり、「robots.txt」によって許可・不許可を指定するのが一般的となっています。
ChatGPTのウェブブラウジングでアクセスしたページのログを見てみると
"GET / HTTP/1.1" 200 2024 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot"
のように記録されていました。
「ChatGPT-User」というボットが来ていたようです。
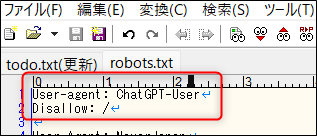
そこで、
User-agent: ChatGPT-User
Disallow: /
...という記述を「robots.txt」に追加しておけばブラウジングをブロックする効果が期待できそうです。
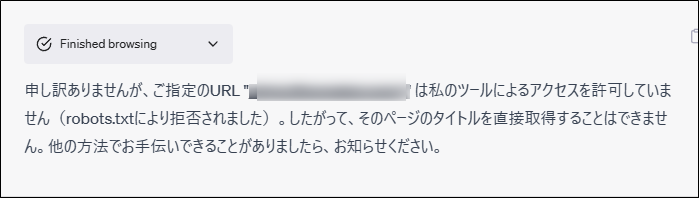
この後ChatGPTのウェブブラウジング機能でアクセスすると、以下のように許可されていないとなりました。
robots.txtの情報もチェックしてくれていたことがわかります。
ChatGPT for Web Developers - firt.dev
(更新)
OpenAIの常時情報収集ボットが「GPTBot」であるとし、不要な場合はその名前でアクセスを制御してほしいと発表しています。
User-agent: GPTBot
Disallow: /