Power Automate Desktopでは、正規表現が使えます。これを使うと、特定の条件の文字だけ見つけ出すということができます。
Power Automate Desktopで正規表現の処理は?

正規表現とは?
アルファベットだけの文字とか、数字だけの文字とかいう条件を検索するための表現です。
これを使えばC#だろうが、PHPだろうが、同じように文字を検索して抜き出すことができます。
Power Automate Desktopでも正規表現が使えます。正規表現を使えば、ファイルやウェブページのHTMLから特定の文字列だけ抜き出して調べることができます。
タグを調べだす
タグを抜き出す正規表現は
<.*?>
を使います。
これは「<」と「>」の間にあるすべての文字という意味になります。
まず「テキスト>テキストの解析」をフローに追加します。
先にテキストをセットしておきます。今回は「FileContents」にHTMLデータを読み込ませています。
検索するテキストで「<.*?>」を、正規表現であるを「オン」に、最初の出現場所を「オフ」にします。
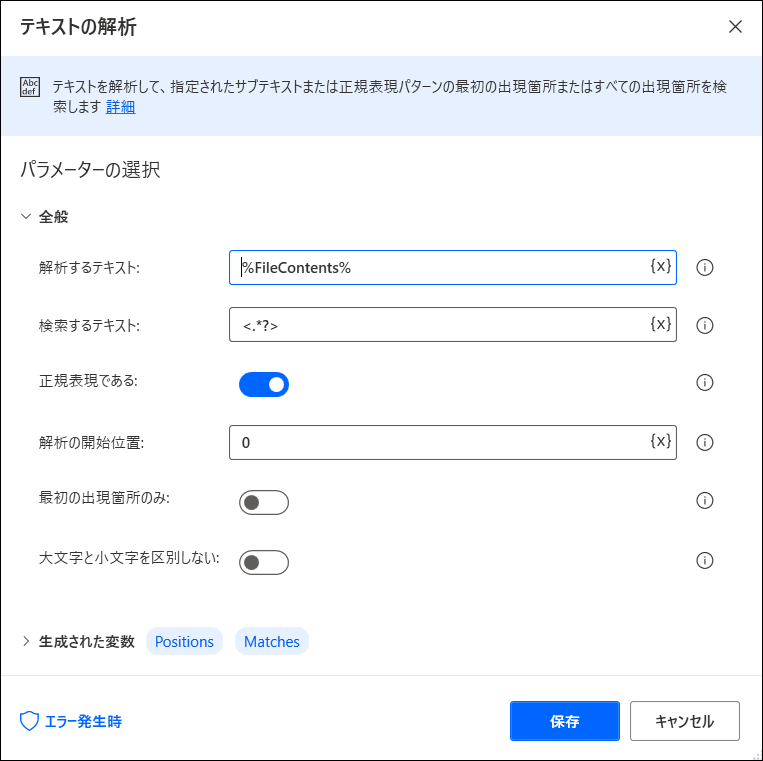
すると開始位置はPositonsという変数に、見つかった文字はMatchesという変数に格納されます。
これで以下のようにフローを作成して実行します。
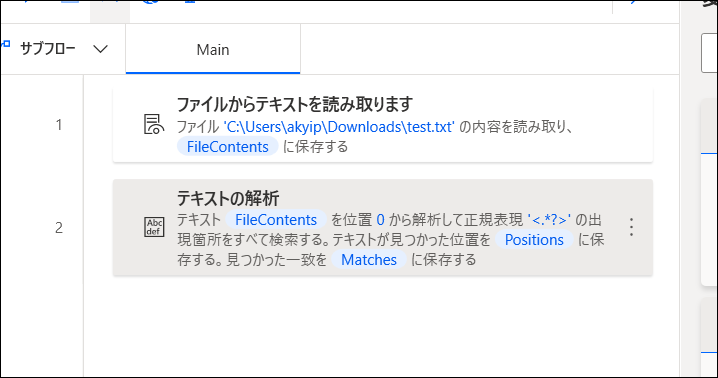
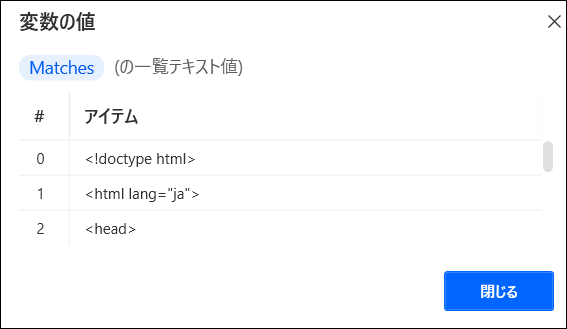
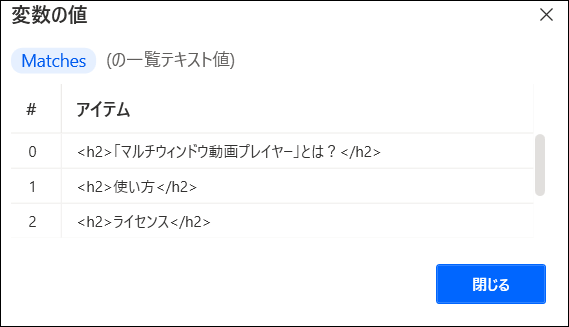
するとMatchesには、以下のように抜き出したタグのリストが入ります。
Postionsには以下のように開始位置のリストが入ります。

特定のタグだけ抜き出す
今回はH2タグだけ抜いてみましょう。
「<h2>.*?</h2>」を使います。
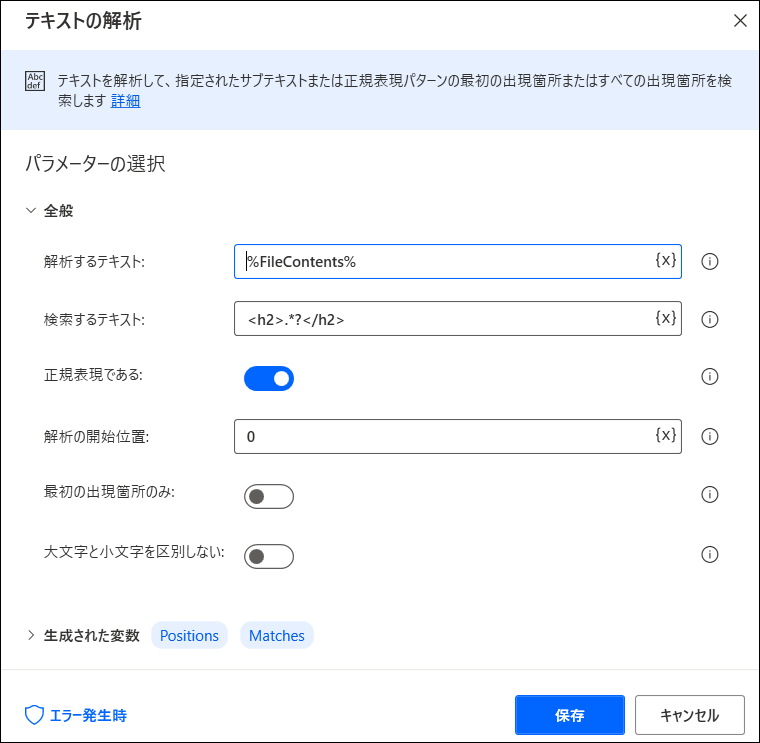
実行すると、以下のようにh2のタグのところだけ取得できました。
Power Automate Desktopの導入方法や基本的な使い方については以下参照ください。